vSphere with Tanzu - SupervisorControlPlaneVM stucks in state NotReady

Failed to get available workloads: bad gateway
The last couple of weeks I spent a lot of time using my Tanzu Kubernetes Cluster(s)1 to get my head around as well as my hands dirty on this awesome project Knative2. More to come soon 😉 Interacting with a healthy vSphere Supervisor Cluster3 is necessary for e.g. the provisioning of new Tanzu Kubernetes Cluster or the instantiation of vSphere Native Pods.
Unfortunately, my attempt to login into mine after a recent power outage ends quicker than expected with the error message:
kubectl vsphere login --server=10.10.18.10 --vsphere-username administrator@jarvis.lab --insecure-skip-tls-verify
Password:
FATA[0004] Failed to get available workloads: bad gateway
Please contact your vSphere server administrator for assistance.My first instinct was to quickly have a look at the Workload Management subsection in the vSphere Client (Menu –> Workload Management or ctrl + alt + 7) and here my suspicion that something is wrong was confirmed. The Config Status of my cluster Malibu was in Configuring state and the following two Status Messages as shown in Figure I were displayed.
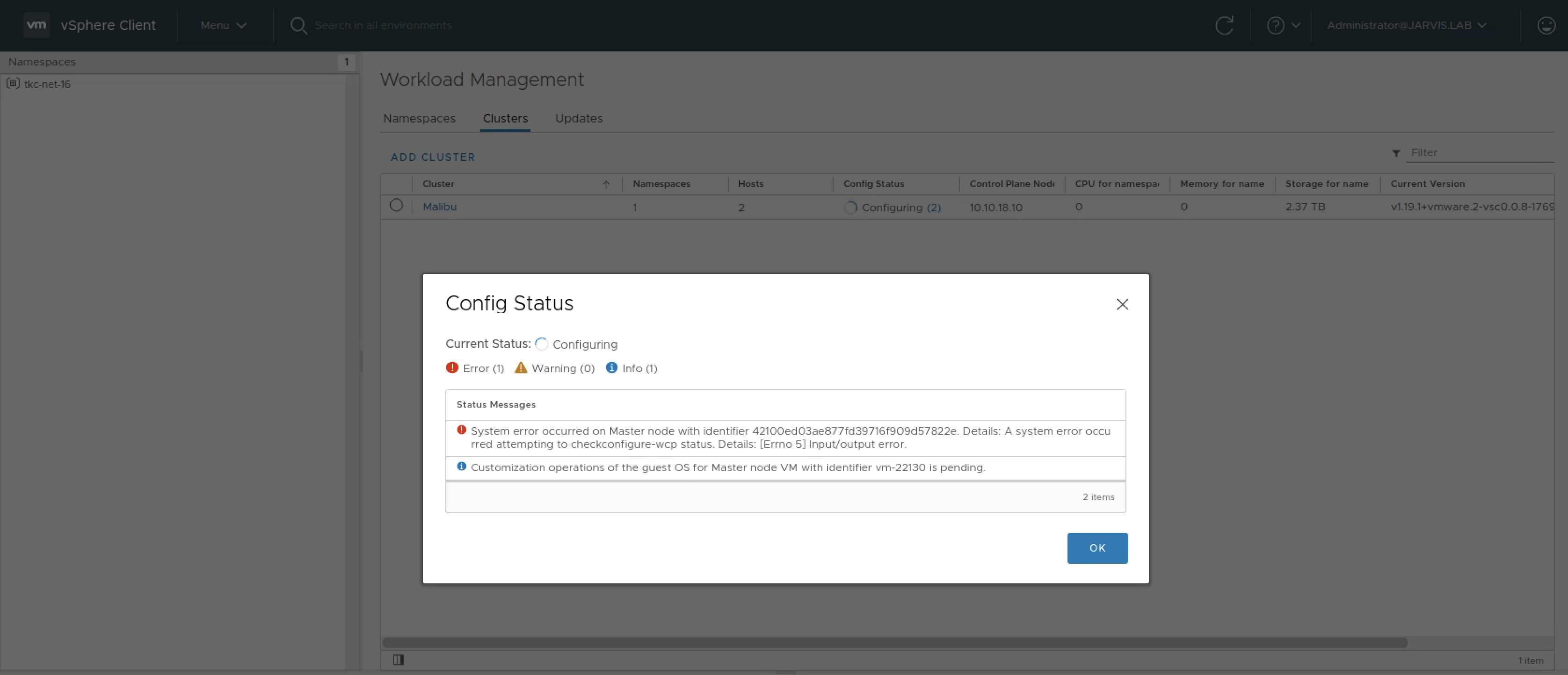
I observed this Configuring state for a while longer and I was hoping it gets fixed automagically but it didn’t.
Seriously, I do believe that this is really due to various (again) circumstances which I was facing with my homelab and normally the desired state (
ready) for the Supervisor Cluster or more specifically, for the Supervisor Control Plane VMs, will be recovered automatically.
Into troubleshooting
HealthState WCP service unhealthy
The next move I did was checking the state of my Tanzu Kubernetes Cluster also via the vSphere Client but they were no longer displayed at all. Things went strange 👻.
Consequently, I checked the overall health of my vCenter Server as well as the health state of the services and especially my attention was on the wcp service (Workload Control Plane). Checking the service state can be done in two ways:
- vCenter Appliance Management Interface aka VAMI (vcenter url:5480)
- via the
shell- which requires an enabled and runningsshservice on the vCenter Server Appliance
The shell output was the following:
root@vcsa [ ~ ]# vmon-cli --status wcp
Name: wcp
Starttype: AUTOMATIC
RunState: STARTED
RunAsUser: root
CurrentRunStateDuration(ms): 72360341
HealthState: UNHEALTHY
FailStop: N/A
MainProcessId: 15679HealthState: UNHEALTHY
And here a little bit more coloured:
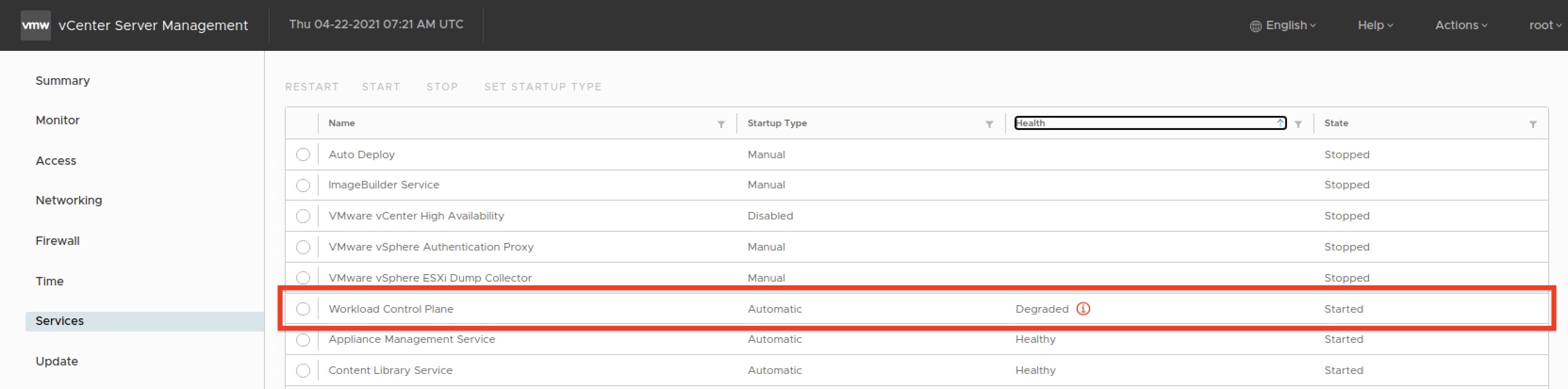
Let’s see if the HealthState will change after restarting the service:
root@vcsa [ ~ ]# vmon-cli --restart wcp
Completed Restart service request.
root@vcsa [ ~ ]# vmon-cli --status wcp
Name: wcp
Starttype: AUTOMATIC
RunState: STARTED
RunAsUser: root
CurrentRunStateDuration(ms): 9709
HealthState: HEALTHY
FailStop: N/A
MainProcessId: 46317HealthState: HEALTHY
Well, way better. Let’s move on from here.
Supervisor Control Plane node status NotReady
Having the wcp service back in operating state led me to start over from where I began. This time logging in to my Supervisor Cluster went well and I checked the state of the three Control Plane Nodes by executing kubectl get nodes.
kubectl get nodes
NAME STATUS ROLES AGE VERSION
42100ed03ae877fd39716f909d57822e NotReady master 7d19h v1.19.1+wcp.2
4210a2e2fa945c1a13308fac6d00ed96 Ready master 7d19h v1.19.1+wcp.2
4210c09deaaa5a2e2ddc86d3e0c0b0f3 Ready master 7d19h v1.19.1+wcp.2Control Plane Node 1: STATUS NotReady
With this new gains, I also checked the Virtual Machine state via the Remote Console and surprisingly, it seems that the power outages affected this particular Node (VM) badly. The Remote Console window was swarmed with error messages saying print_req_error: I/O error, dev sda, sector ...[counting up]
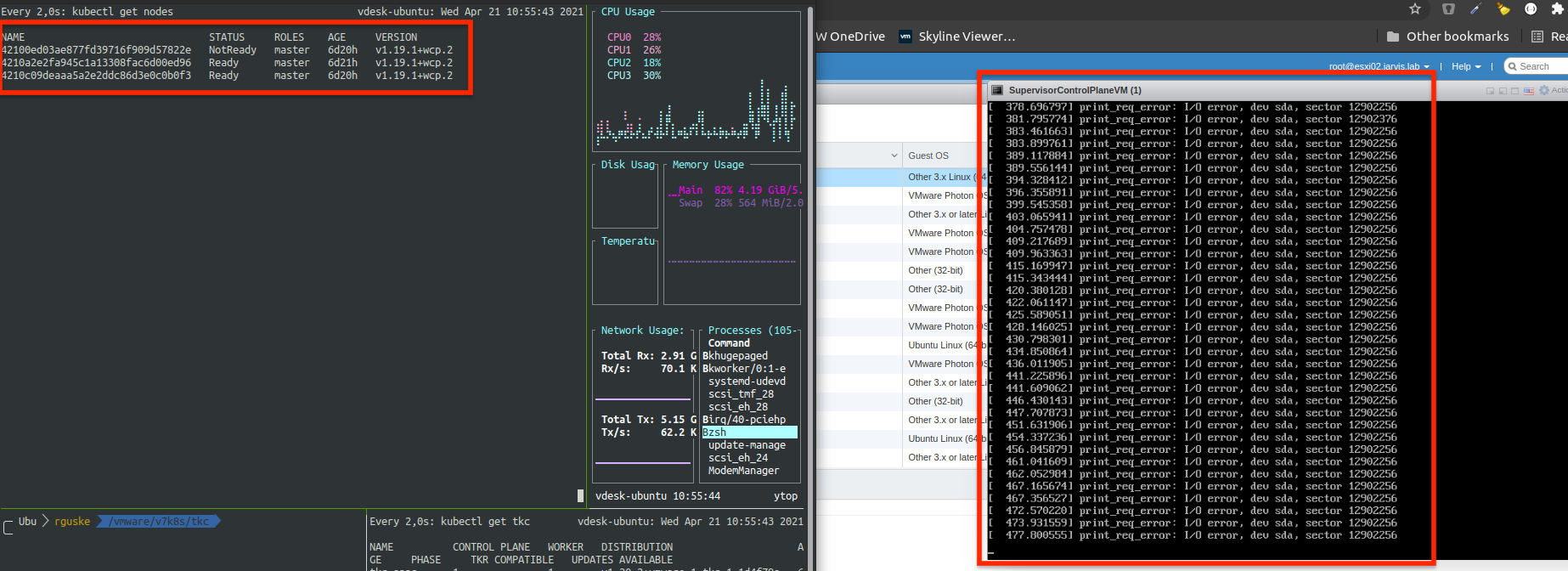
I was also trying to figure out if there’s a way to get this fixed on the Operating System level but there was no chance or at least there wasn’t one for my expertise.
vSphere ESXi Agent Manager
Updated November, 2023
I was ask by our Global Support Services team to add the following statement to this article. Please read it carefully.
Do not delete eam agencies without the EXPRESS permission of a VMware support engineer. Depending on versions and the existing health of the supervisor cluster it is entirely possible to render the entire cluster un-recoverable. If VMware Support finds evidence of a customer manually deleting an EAM Agency, they may mark your cluster as unsupported and require you redeploy the entire vSphere with Tanzu solution.
Read VMware KB90194
Proceeding from here is on your own risk.
If the desired state cannot be recovered automatically again, what option remains?
Well, there’s always something to learn. My well appreciated colleague Dominik Zorgnotti was pointing me to the vSphere ESXi Agent Manager (EAM), which in the end turned out to be the solution for my problem. To be honest, I never was in the situation to make use of the EAM before and therefore it wasn’t on my radar at all but I was quite happy to get to know this component now. What it does?
You will find the EAM in the vSphere Client under Menu -> Administration -> vCenter Server Extensions -> vSphere ESXi Agent Manager.
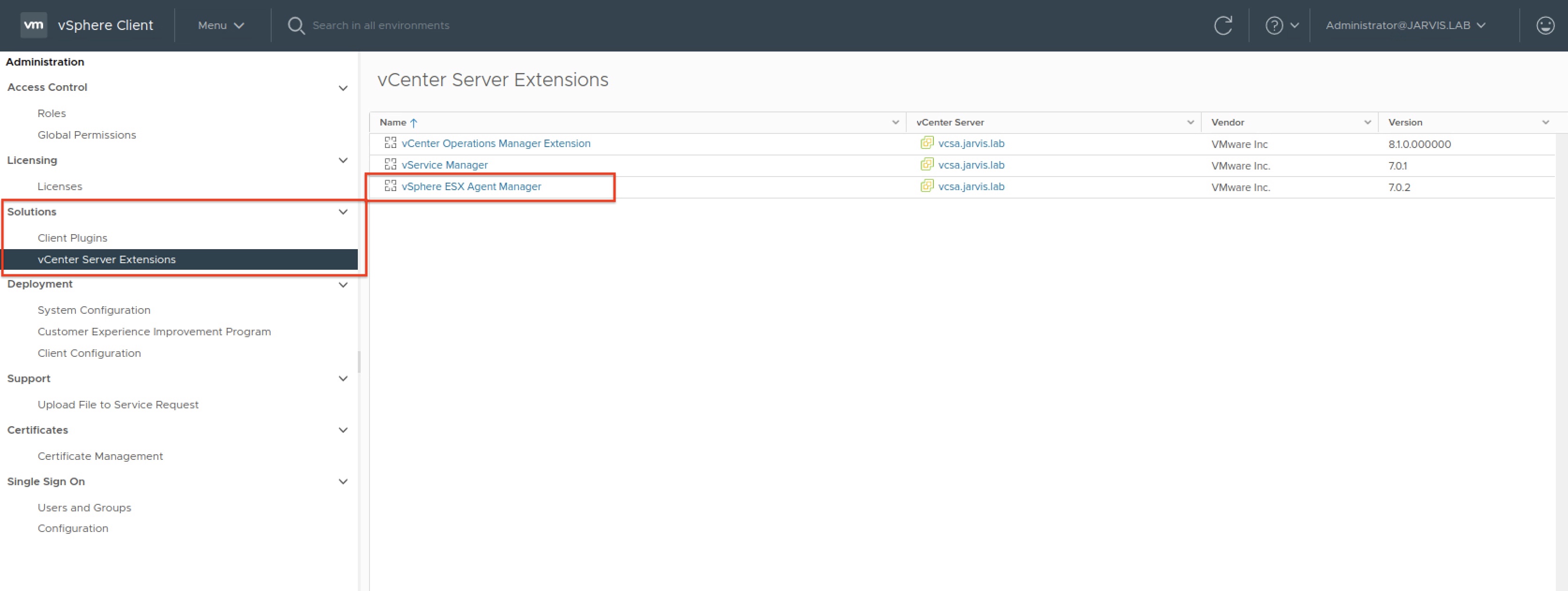
The three Supervisor Control Plane VMs can be found via the Configure tab and are listed in the column as Agency named with prefix vmware-vsc-apiserver-xxxxxx. By selecting the three dots besides the name, it gives us the two options Delete Agency as well as Remove All Issues. See Figure V.
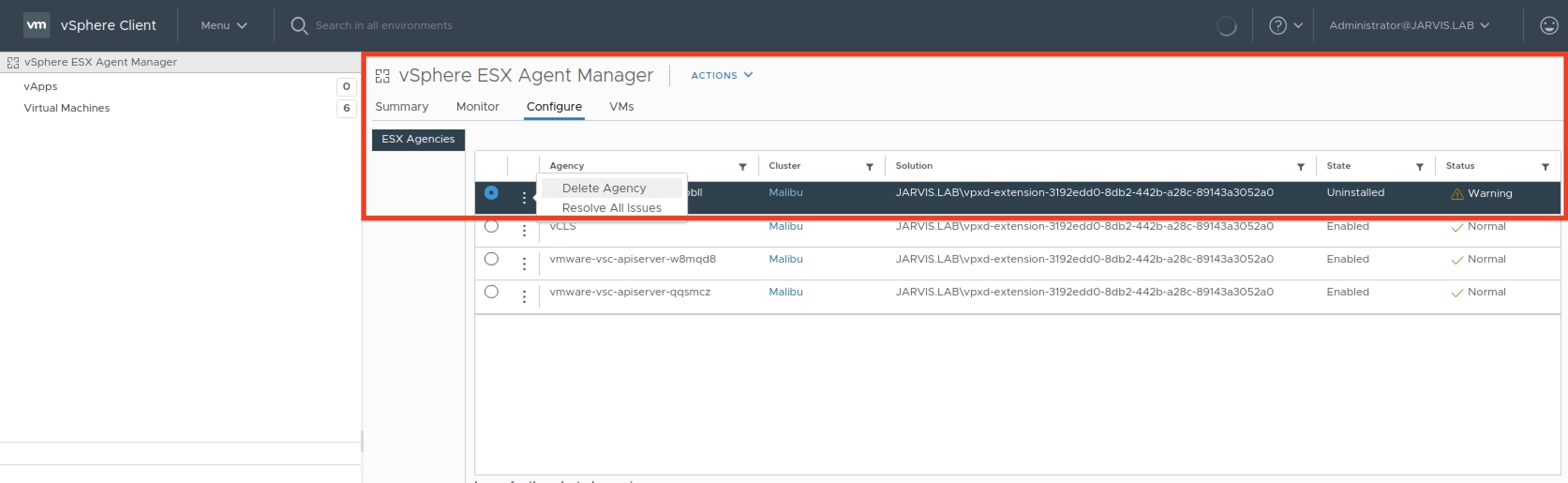
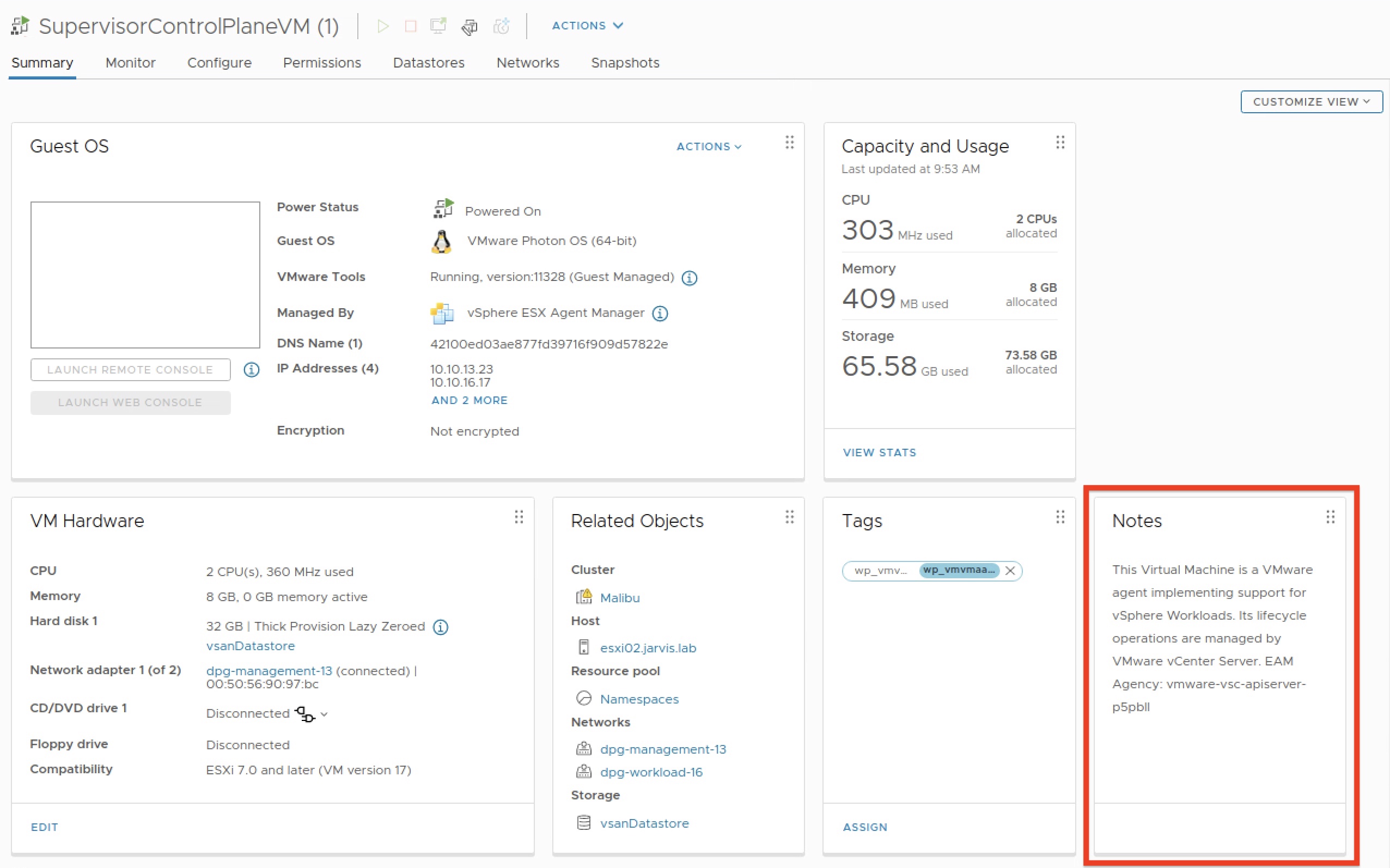
But which of the three “Agency’s” is our affected one? I’ve never recognized this used naming pattern before, not in the vSphere Client nor by using kubectl (e.g. kubectl describe node). Ultimately, I took a look at the summary page of the VM and the Notes widget enlightened me.
This Virtual Machine is a VMware agent implementing support for vSphere Workloads. Its lifecycle operations are managed by VMware vCenter Server. EAM Agency: vmware-vsc-apiserver-w8mqd8
See also Figure VI:
Having found the missing piece, I first went with the Remove All Issues option but it didn’t solve my problem.
With having in mind, that the Supervisor Cluster is a high available construct consisting of three members and it’s current degraded state, I checked twice if the one I picked is the right one before hitting the Delete Agency 🔴 button.
Immediately thereafter, the affected VM got deleted and a new one was on it’s way.
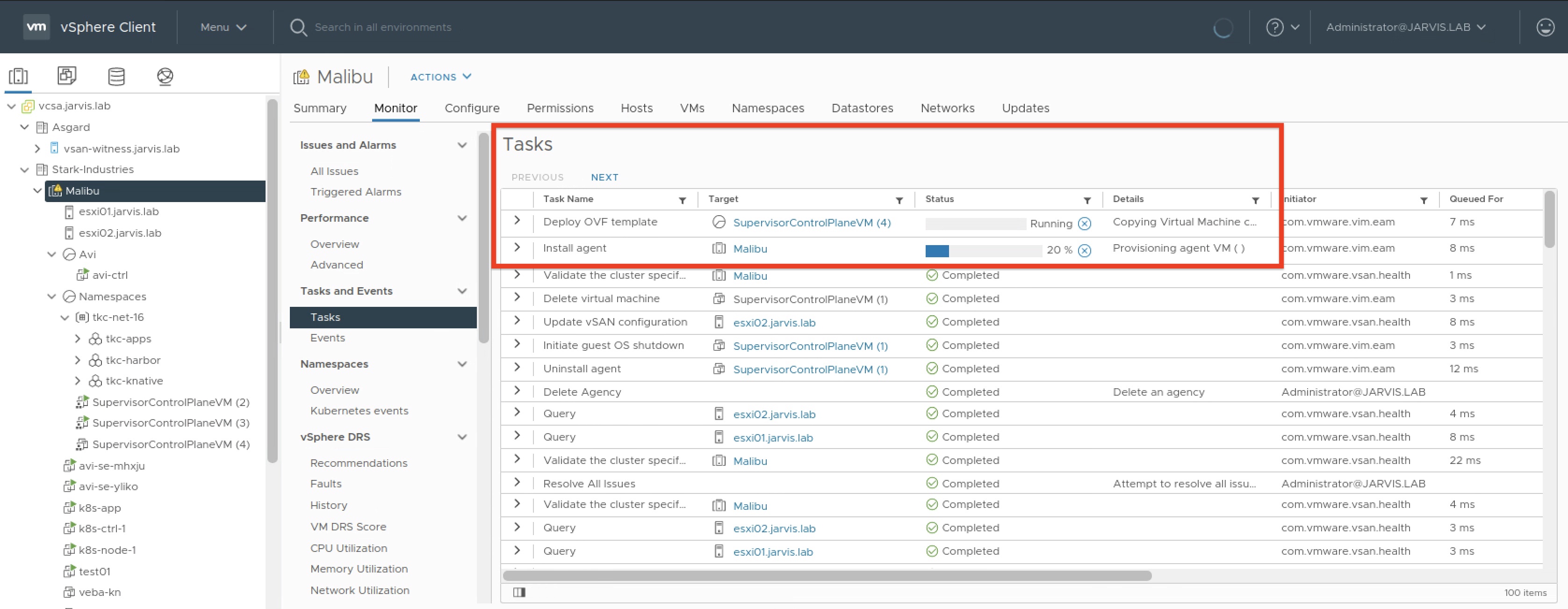
At the end, my cluster reached the Config Status Running, all three Nodes were Ready and the wcp service never became (until now) unhealthy again.

kubectl get nodes
NAME STATUS ROLES AGE VERSION
42103deb5d43d5f75f4623a336165684 Ready master 3m37s v1.19.1+wcp.2
4210a2e2fa945c1a13308fac6d00ed96 Ready master 7d20h v1.19.1+wcp.2
4210c09deaaa5a2e2ddc86d3e0c0b0f3 Ready master 7d20h v1.19.1+wcp.2