vSphere with Tanzu - Troubleshooting HAProxy deployment
Introduction
You may have already heard and read about our latest changes regarding our Kubernetes offering(s) vSphere with Tanzu also former known as vSphere with Kubernetes. Personally, I was totally excited and full of anticipation to make my first hands-on experience with this new deployment option –> vSphere Networking as an alternative to NSX-T and how HAProxy is doing it’s job within this construct. I don’t know how you are dealing with installations of the “NEW” but I always read the documentation first… … not … 🙊 … but I should!
Honestly! Doesn’t matter of which kind of implementation we are talking, is it a Homelab (test environment), a Proof of Concept implementation or in production, our final goal is a working solution and this is why we should be prepared best. Through this article, I will even more stress this point because I did a mistake which did cost me time in troubleshooting the failure I’ve received. On the other hand and “as always”, it enlightened me and enriched my wealth of experience.
Preperations
This article will not describe the vSphere with Tanzu installation itself. For this kind of details, I would like to point you to VMware’s official documentation or to this vSphere with Tanzu Quick Start Guide V1a (for evaluation purposes) which VMware is maintaining on the Cloud Platform Tech Zone.
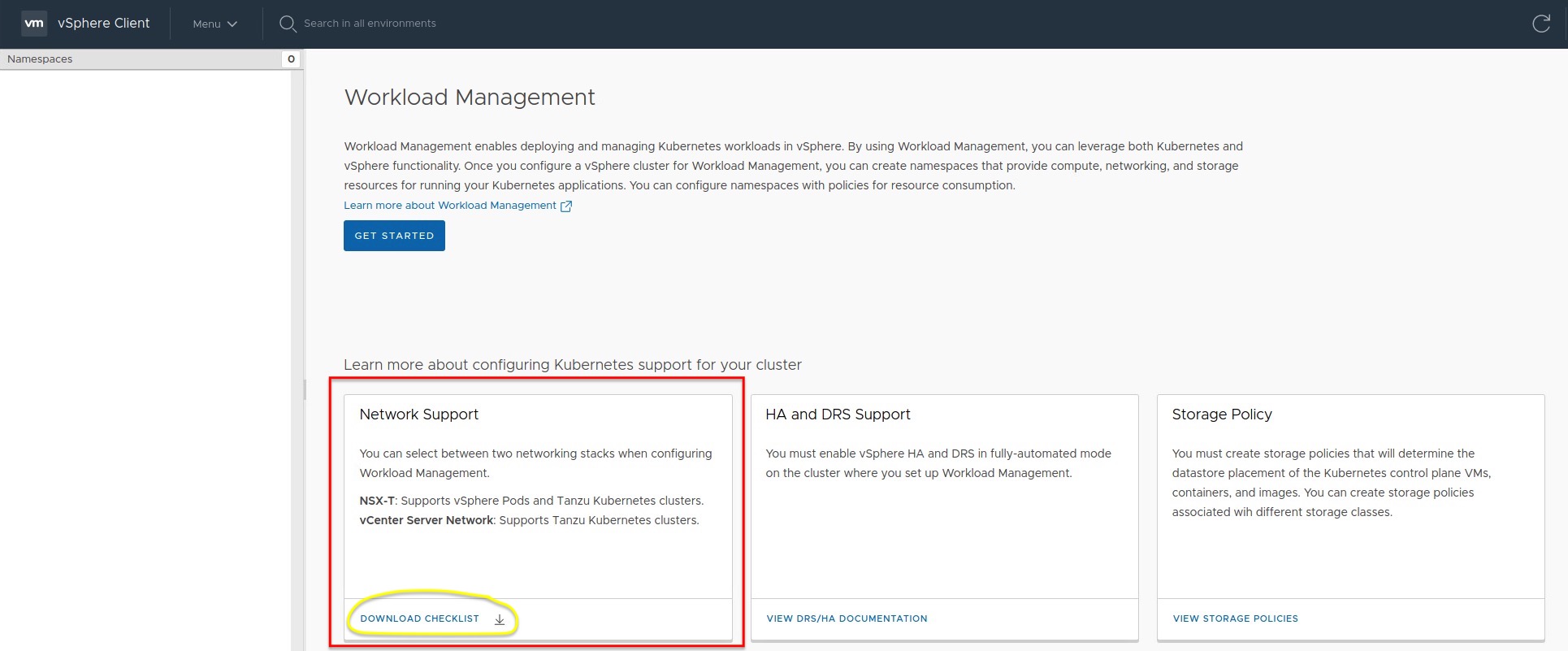
Also! For being prepared better as well as for documentation purposes, we are providing a checklist-file which can be downloaded through the Workload Management section in the vSphere Client and then shared or forwarded to the networking engineer of your confidence (Figure I).
Resources
- VMware Docs - vSphere with Tanzu Basics
- VMware Cloud Platform Tech Zone - vSphere with Tanzu Quick Start Guide V1a
- - HAProxy Direct Download Link
- - HAProxy Powershell/PowerCLI Deployment Script
- - HAProxy Build the Appliance from scratch
- Blogs:
The Frontend Network
Step 6 in the Quick Start Guide describes the deployment of the HAProxy Virtual Appliance on vSphere. OVA deployment step 7 gives us the ability to deploy HAProxy with an additional network interface to seperate the Kubernetes nodes of our clusters from the network used by clients or services to access these clusters (Figure II).
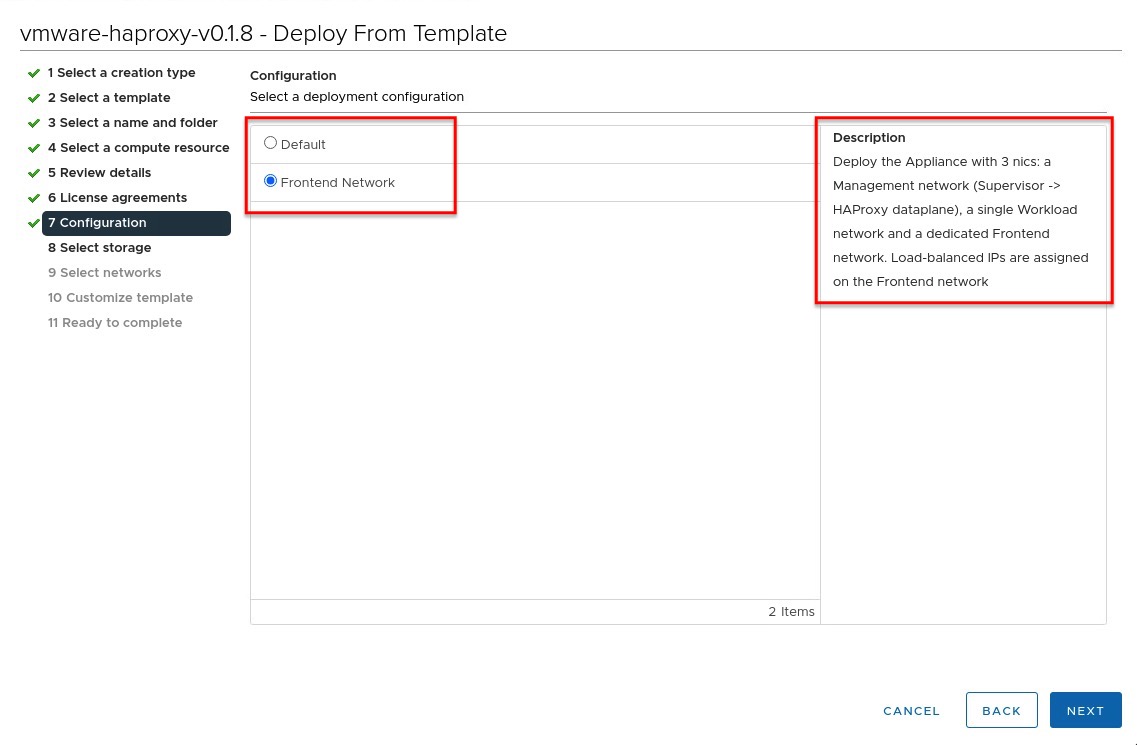
The configuration of the additional Frontend network is not covered through the aforementioned Quick Start Guide (for simplicity reasons) but if you are going to deploy vSphere with Tanzu into production, it definitely should be used.
I tried to simplify the traffic flow coming from the client and/ or service through the Kubernetes clusters roughly via the following chart:
It must be a valid Subnetwork
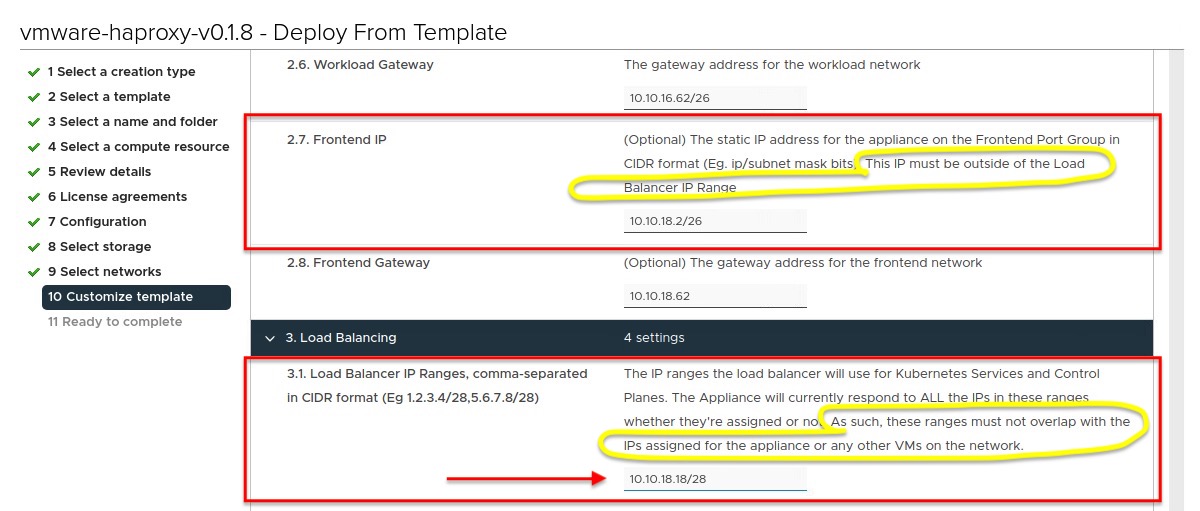
OVA deployment step 2.7 requests the static IP address for the Frontend interface and this IP must be outside of the Load Balancer IP Range which you have to define in the next step 3.1. Furthermore, this IP range should not overlap with the assigned IP address of the Frontend network interface as well as with any other VMs in this range!
I’ve misinterpreted the description for Loadbalancer IP ranges in step 3.1 (see Figure III) which I should have “painfully” realised after the complete deployment.
At this point, I’d like to make a little excursion in networking 101 to make sure you also see my mistake which I’ve made through this misinterpretation. I entered 10.10.18.18/28 as an IP range which isn’t a valid Subnetwork. A valid subnetwork configuration for my evaluation deployment should have looked like:
| Description | Address |
|---|---|
| Network ID | 10.10.18.16 |
| Broadcast | 10.10.18.31 |
| Netmask | 255.255.255.240 |
| Host IP starts with | 10.10.18.17 |
| Host IP ends with | 10.10.18.30 |
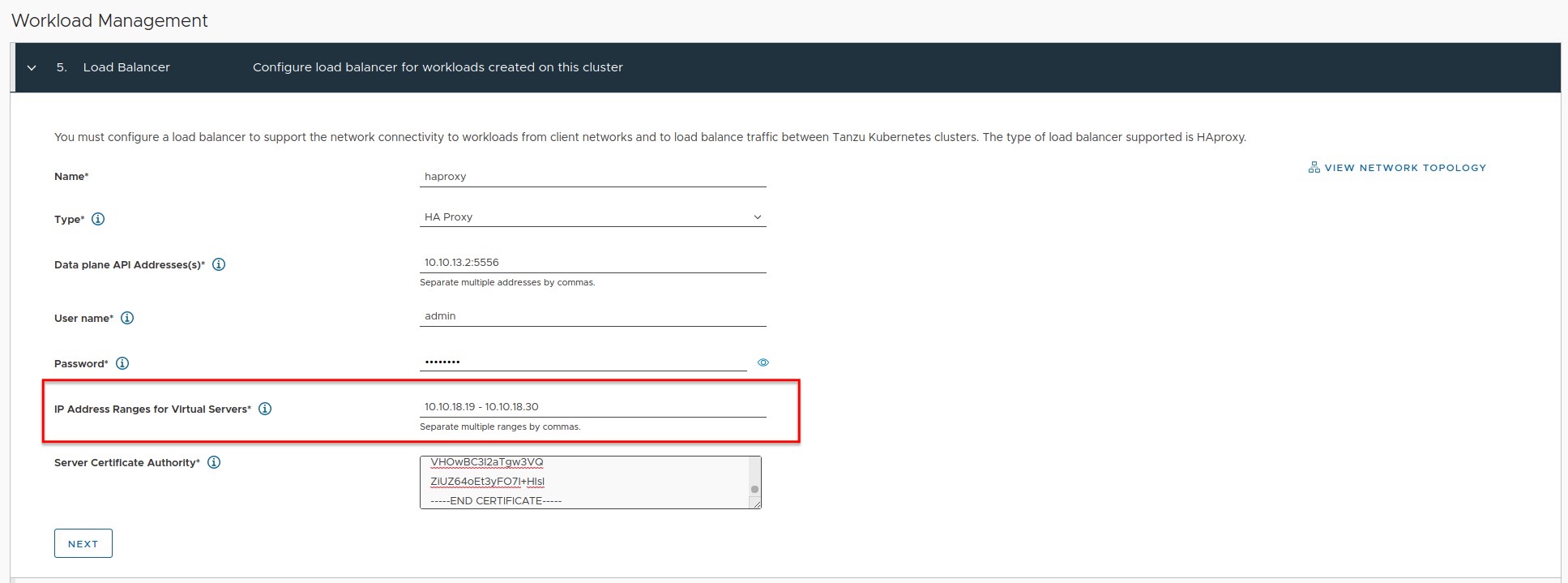
10.10.18.16/28 is valid and because I decided to use a /28 network, the available IPs for the virtual server range, which you have to provide in Step 5 in the Workload Management configuration (Figure IV) later on, starts with .17 and ends with .30.
The following table gives you a quick overview of available Host IPs for a specific subnetwork.
| Subnet Mask | /29 | /28 | /27 | /26 | /25 | /24 |
|---|---|---|---|---|---|---|
| Host IPs | 6 | 14 | 30 | 62 | 162 | 254 |
* I excluded Network-ID and Broadcast-ID
Don’t be confused
The following has nothing to do with the actual problem but the hint could avoid an uncertainty. Figure V shows the configuration summary of Step 5 and Ingress CIDR/ IP Ranges: 10.10.18.19/11 (in my example) could be confusing because of the CIDR notation.
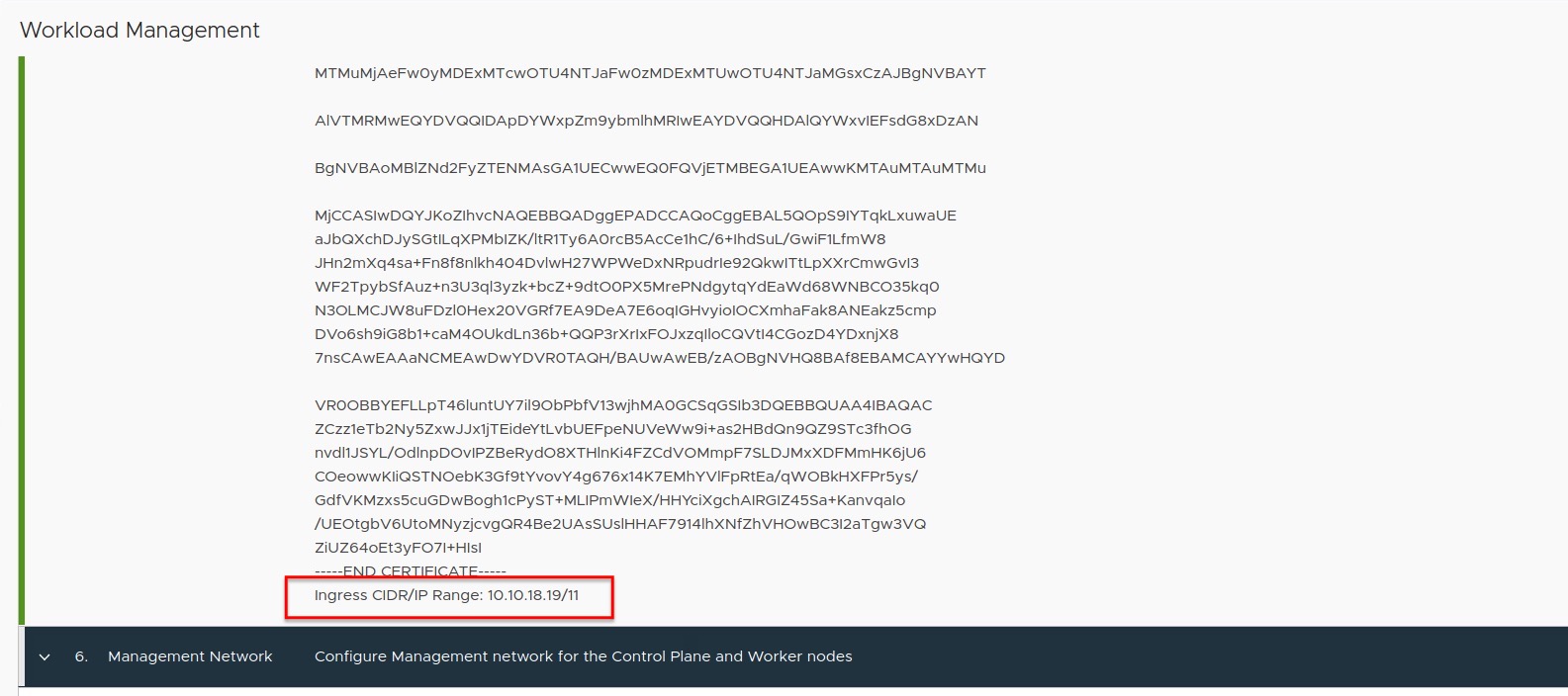
What it shows, is the first IP - .19 - and the maximum number of remaining IPs - /11 - for your defined IP Ranges for Virtual Servers.
Connect: No route to host.
At first sight, the installation seems to be successful and the Cluster Config Status in the vSphere client doesn’t indicate the opposite (Figure VI).

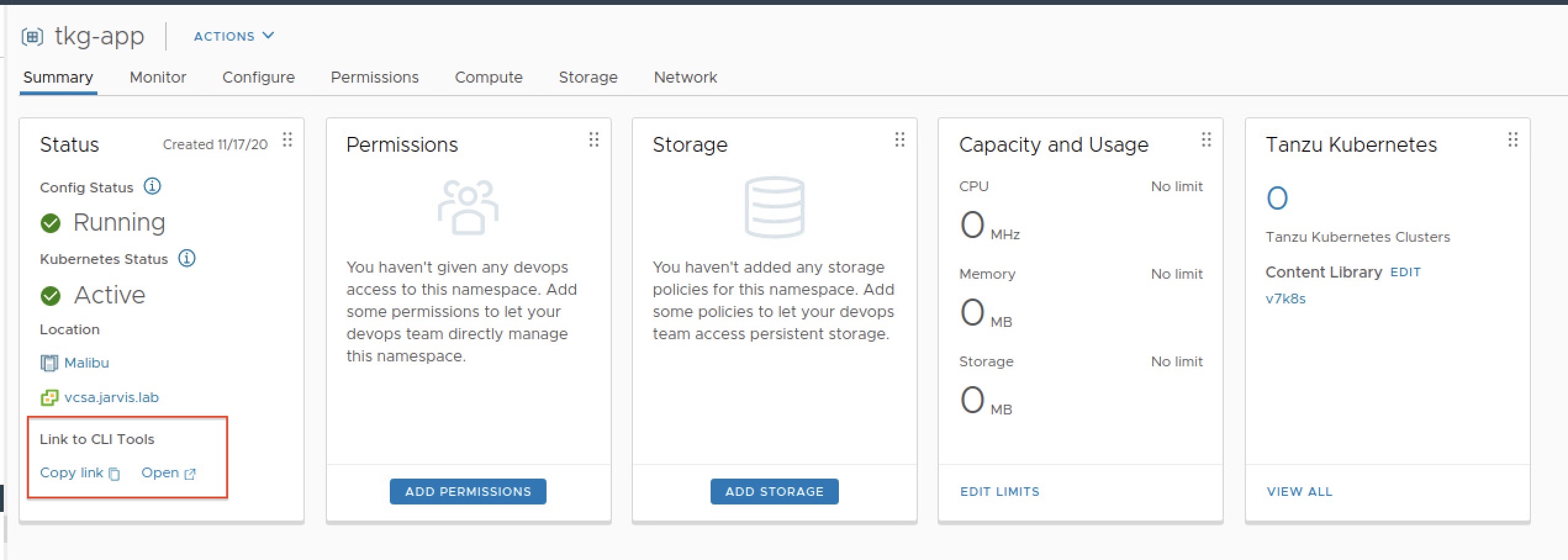
But appearances are deceptive! I created a vSphere Namespace to deploy a Tanzu Kubernetes Cluster (Guest Cluster) and clicked on the OPEN button/ link to the CLI tools (Figure VII) to check the reachability of my Supervisor Cluster and got an ERR_ADDRESS_UNREACHABLE back.
Of course that made me suspicious and I tried to login via kubectl vsphere login:
kubectl vsphere login --insecure-skip-tls-verify --vsphere-username administrator@jarvis.lab --server=10.10.18.19
and got the following error:
HAProxy Frontend VIP bind service
Having a look at my above drawing it shows us that our incoming request tries to reach the Frontend VIP 10.10.18.19 trough HAProxy. Because HAProxy is providing those VIP’s, it’s logical to start troubleshooting the HAProxy appliance first. SSH is enabled by default.
I started with a simple status check of all services by executing systemctl status. The output was surprisingly degraded.
Let`s narrow it down!
root@haproxy [ / ]# systemctl list-units --state=failed
UNIT LOAD ACTIVE SUB DESCRIPTION
● anyip-routes.service loaded failed failed anyip-routes.service
● haproxy.service loaded failed failed HAProxy Load Balancer
● route-tables.service loaded failed failed route-tables.serviceThree services have failed to start. I’m starting from the top with verifying the anyip-routes.service.
root@haproxy [ / ]# systemctl status anyip-routes.service
● anyip-routes.service
Loaded: loaded (/etc/systemd/system/anyip-routes.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Fri 2020-11-20 15:30:07 UTC; 3min 5s ago
Process: 783 ExecStopPost=/var/lib/vmware/anyiproutectl.sh down (code=exited, status=0/SUCCESS)
Process: 777 ExecStartPre=/var/lib/vmware/anyiproutectl.sh up (code=exited, status=2)
Process: 776 ExecStartPre=/bin/mkdir -p /var/log/vmware (code=exited, status=0/SUCCESS)
Nov 20 15:30:07 haproxy.jarvis.lab systemd[1]: Starting anyip-routes.service...
Nov 20 15:30:07 haproxy.jarvis.lab anyiproutectl.sh[777]: adding route for 10.10.18.18/28
Nov 20 15:30:07 haproxy.jarvis.lab anyiproutectl.sh[777]: RTNETLINK answers: Invalid argument
Nov 20 15:30:07 haproxy.jarvis.lab systemd[1]: anyip-routes.service: Control process exited, code=exited status=2
Nov 20 15:30:07 haproxy.jarvis.lab systemd[1]: anyip-routes.service: Failed with result 'exit-code'.
Nov 20 15:30:07 haproxy.jarvis.lab systemd[1]: Failed to start anyip-routes.service.The mentioned script in this line Process: 783 ExecStopPost=/var/lib/vmware/anyiproutectl.sh down (code=exited, status=0/SUCCESS) seems to do something and by reviewing it, I found the following hint to the configuration file location for the broken service.
[...]
# The path to the config file used by this program.
CONFIG_FILE="${CONFIG_FILE:-/etc/vmware/anyip-routes.cfg}"
[...]root@haproxy [ /etc/vmware ]# cat anyip-routes.cfg
#
# Configuration file that contains a line-delimited list of CIDR values
# that define the network ranges used to bind the load balancer's frontends
# to virtual IP addresses.
#
# * Lines beginning with a comment character, #, are ignored
# * This file is used by the anyip-routes service
#
10.10.18.18/28Verifying the file and thus my made configuration finally brought me enlightenment. I changed it consequently from 10.10.18.18/28 to a valid Subnetwork range, which is the already mentioned 10.10.18.16/28 and rebooted the HAProxy appliance (reboot). Just restarting the service with systemctl restart anyip-routes.service does not apply all necessary changes.
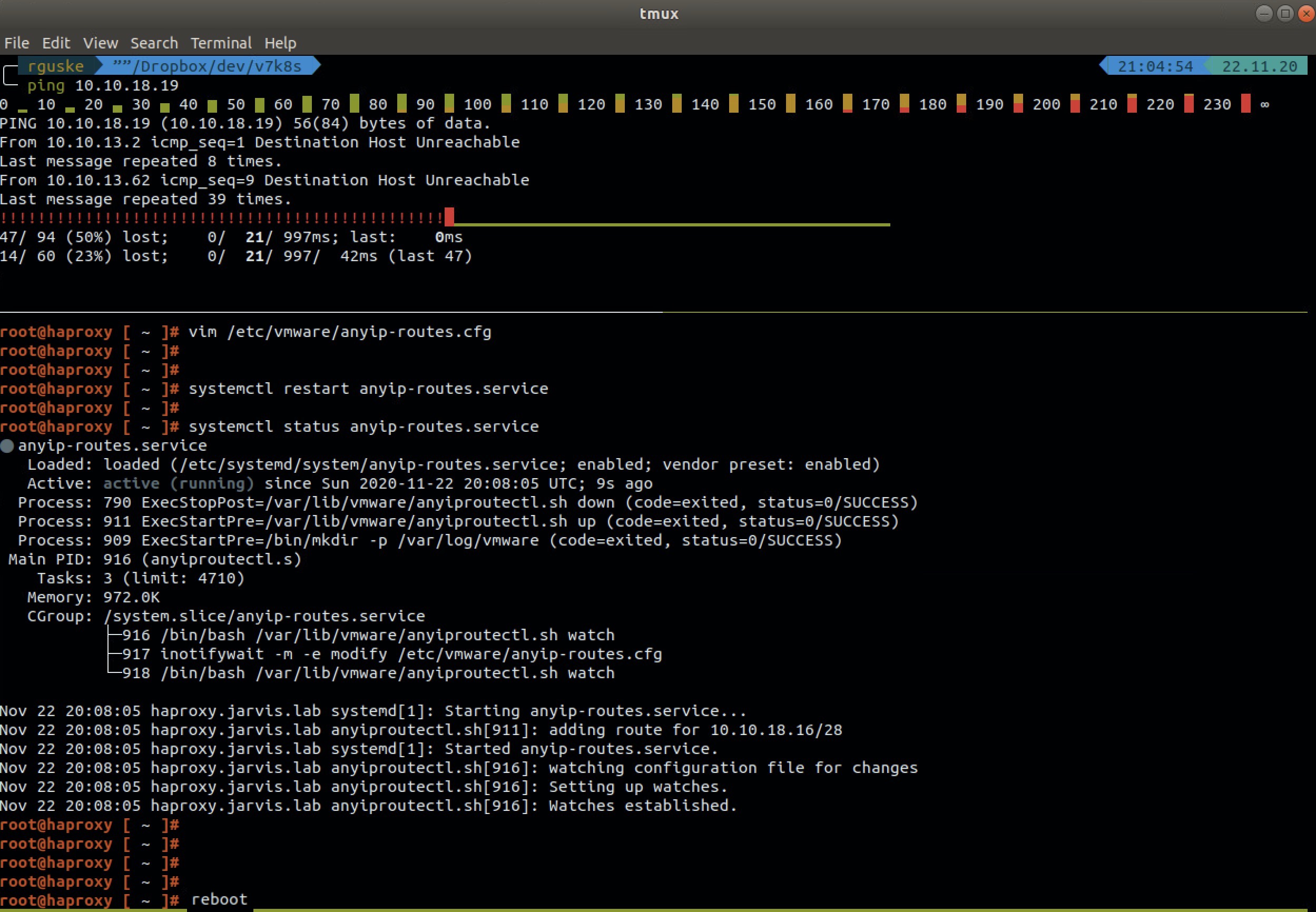
Finally, the validation of the restored functionality:
kubectl vsphere login --insecure-skip-tls-verify --vsphere-username administrator@jarvis.lab --server=10.10.18.19
Password:
Logged in successfully.
You have access to the following contexts:
10.10.18.19
tkg-app
If the context you wish to use is not in this list, you may need to try
logging in again later, or contact your cluster administrator.
To change context, use `kubectl config use-context <workload name>